8장 경계 간 매핑하기
- 각 계층의 모델을 매핑하는 것에 대한 논쟁
- 매핑에 찬성하는 개발자 : 두 계층 간에 매핑을 하지 않으면 양 계층에서 같은 모델을 사용해야 하는데 이렇게 하면 두 계층이 강하게 결합된다.
- 매핑에 반대하는 개발자 : 두 계층 간에 매핑을 하게 되면 보일러플레이트 코드를 너무 많이 만들게 되어서 많은 유스케이스들이 오직 CRUD만 수행하고 계층에 걸쳐 같은 모델을 사용하기 때문에 계층 사이의 매핑은 과하다.
'매핑하지 않기' 전략

웹 계층에서 웹 컨트롤러가 SendMoneyUseCase 인터페이스를 호출해 유스케이스를 실행한다. 이 인터페이스는 Account 객체를 인자로 가진다. 웹 계층과 애플리케이션 계층 모두 Account 클래스에 접근한다 (두 계층이 같은 모델을 사용)
반대쪽의 영속성 계층, 애플리케이션도 마찬가지다. 모든 계층이 같은 모델을 사용하기 때문에 계층 간 매핑을 할 필요가 없다.
이러한 설개의 결과는 도메인과 애플리케이션 계층은 웹이나 영속성과 관련된 특수한 요구사항에 관심이 없음에도 Account 도메인 모델 클래스는 이런 모든 요구사항을 다뤄야 한다.
Account 클래스는 웹, 애플리케이션, 영속성 계층과 관련된 이유로 인해 변경되어야 하기 때문에 단일 책임 원칙을 위반하게 된다.
간단한 CRUD 유스케이스의 경우, 모든 계층이 정확하게 같은 구조의, 정확히 같은 정보를 필요로 한다면 '매핑하지 않기' 전략이 좋은 선택지가 되어줄수 있다.
'양방향' 매핑 전략
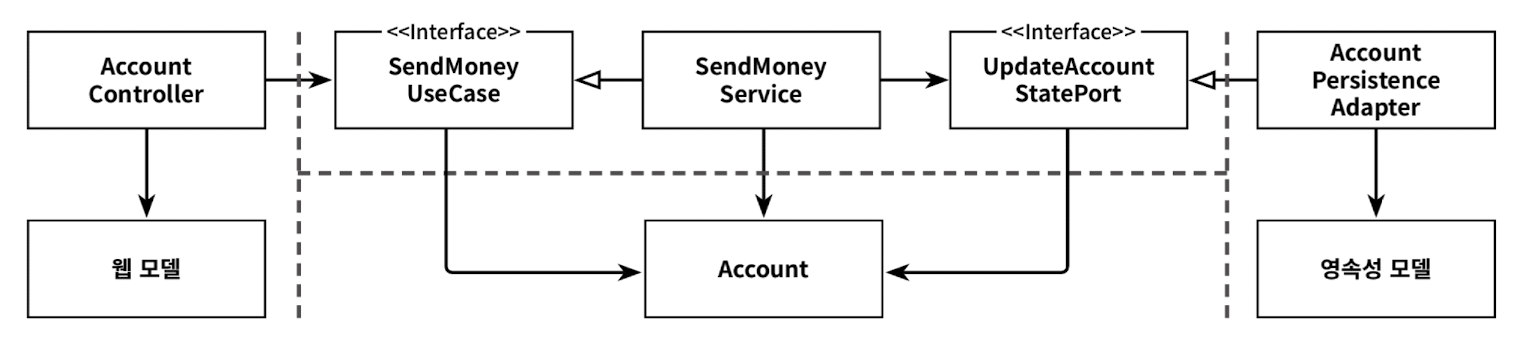
각 계층은 도메인 모델과 다른 완전히 다른 구조의 전용 모델을 가지고 있다.
웹 계층에서는 웹 모델을 인커밍 포트에서 필요한 도메인 모델로 매핑하고, 인커밍 포트에 의해 반환된 도메인 객체를 다시 웹 모델로 매핑한다. 영속성 계층도 마찬가지로 아웃고잉 포트가 사용하는 도메인 모델과 영속성 모델 간의 매핑과 유사한 매핑을 담당한다. 두 계층 모두 양방향으로 매핑하기 때문에 '양방향' 매핑이라고 부른다.
이 매핑 전략은 웹이나 영속성 관심사로 오염되지 않은 깨끗한 도메인 모델로 이어진다. JSON이나 ORM 매핑 애너테이션없이 단일 책임 원칙을 만족할 수 있게 해준다.
'양방향' 매핑의 또 다른 장점은 간단하게 매핑 책임이 명확하다. 바깥쪽 계층/어댑터는 안쪽 계층의 모델로 매핑하고, 다시 반대 방향으로 매핑한다. 안쪽 계층은 해당 계층의 모델만 알면 되고 매핑대신 도메인 로직에 집중할 수 있게 된다.
단점으로는 너무 많은 보일러플레이트 코드가 생긴다는 것과 도메인 모델이 계층 경계를 넘어서 통신하는 데 사용되고 있다는 것이다. 인커밍 포트와 아웃고잉 포트는 도메인 객체를 입력 파라미터와 반환값으로 사용한다. 도메인 모델은 도메인 모델의 필요에 의해서만 변경되는 것이 이상적이지만 바깥쪽 계층의 요구에 따른 변경에 취약해진다.
'매핑하지 않기' 전략과 '양방향' 매핑 전략 둘 다 정답은 없고 철칙도 아니다. 각 유스케이스마다 적절한 전략을 택할 수 있어야 한다.
'완전' 매핑 전략
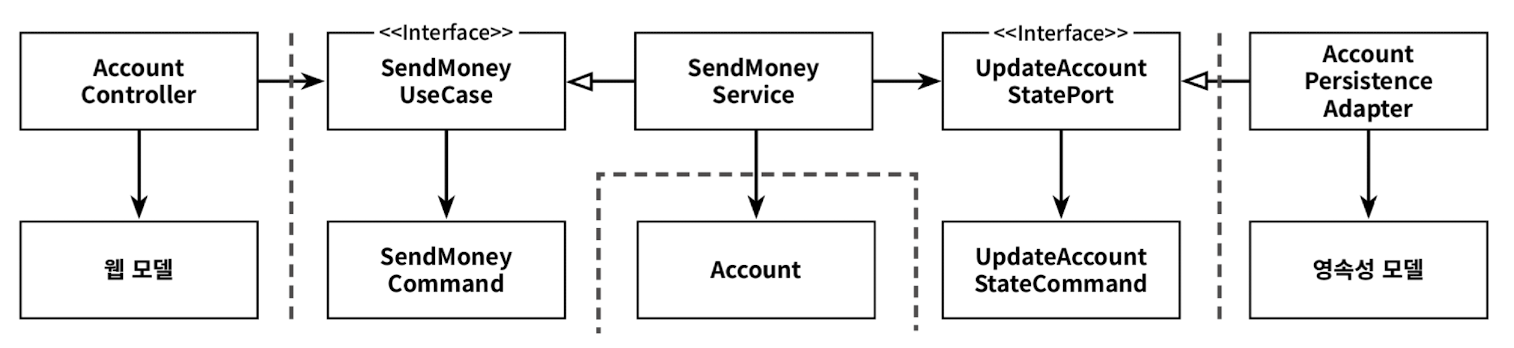
완전매핑 전략에서는 각 연산마다 별도의 입출력 모델을 사용한다. SendMoneyUseCase 포트의 입력 모델로 동작하는 SendMoneyCommand 처럼 각 작업에 특화된 모델을 사용한다. 이런 모델을 가리켜 command, request 혹은 이와 비슷한 단어로 표현한다.
웹 계층은 입력을 애플리케이션 계층의 커맨드 객체로 매핑할 책임을 가지고 있다. 이러한 커맨드 객체는 애플리케이션 계층의 인터페이스를 해석할 여지 없이 명확하게 만들어준다. 여러 유스케이스의 요구사항을 함께 다뤄야 하는 매핑에 비해 구현하고 유지보수하기가 훨씬 쉽다.
이 매핑 전략은 전역 패턴으로 추천하지는 않는다. 이 전략은 웹 계층(혹은 인커밍 어댑터 종류 중 아무거나)과 애플리케이션 계층 사이에서 상태 변경 유스케이스의 경계를 명확하게 할 때 가장 빛을 발한다. 애플리케이션 계층과 영속성 계층 사이에서는 매핑 오버헤드 때문에 사용하지 않는것이 좋다
매핑 전략은 여러 가지를 섞어쓸 수 있고, 섞어 써야만 한다. 어떤 매핑 전략도 모든 계층에 걸쳐 전역 규칙일 필요가 없다
'단방향 매핑 전략'

모든 계층의 모델들이 같은 인터페이스를 구현한다. 인터페이스는 관련 있는 특성(attribute)에 대한 getter 메서드를 제공해서 도메인 모델의 상태를 캡슐화 한다.
도메인 모델 자체는 풍부한 행동을 구현할 수 있고, 애플리케이션 계층 내ㅑ의 서비스에서 이런 행동에 접근할 수 있다. 도메인 객체를 바깥 계층으로 전달하고 싶으면 매핑없이 할 수 있다. 도메인 객체가 인커밍/아웃고잉 포트가 기대하는 대로 상태 인터페이스를 구현하고 있기 때문이다.
바깥 계층에서는 상태 인터페이스를 이용할지, 전용 모델로 매핑해야 할지 결정할 수 있다. 이 전략에서 매핑 책임은 명확하다 만약 한 계층이 다른 계층으로부터 객체를 받으면 해당 계층에서 이용할 수 있도록 다른 무언가로 매핑하는 것이다. 각 계층은 한 방향으로만 매핑한다. 그래서 이 전략의 이름이 '단방향' 매핑이다. 이 전략은 계층 간의 모델이 비슷할 때 가장 효과적이다. 읽기 전용 연산의 경우 상태 인터페이스가 필요한 모든 정보를 제공하기 때문에 웹 계층에서 전용 모델로 매핑할 필요가 없다.
언제 어떤 매핑 전략을 사용할 것인가?
이 질문의 답은 '그때그때 다르다' 팀 내에서 가이드라인을 정해둬야 하며, 어떤 상황에서 어떤 매핑 전략을 가장 먼저 택해야 하는가에 답할 수 있어야 한다.
- 예를 들어
- 변경 유스케이스를 작업하고 있다면 웹 계층과 애플리케이션 계층 사이에서는 유스케이스간의 결합을 제거하기 위해 '완전 매핑' 전략을 첫 번째 선택지로 택해야 한다. 이렇게 하면 유스케이스별 유효성 검증 규칙이 명확해지고 특정 유스케이스에서 필요하지 않은 필드를 다루지 않는다.
- 변경 유스케이스를 작업하고 있다면 애플리케이션과 영속성 계층 사이에서는 매핑 오버헤드를 줄이고 빠르게 코드를 짜기 위해서 '매핑하지 않기' 전략을 첫 번째 선택지로 둔다. 하지만 애플리케이션 계층에서 영속성 문제를 다뤄야 하게 되면 '양방향' 매핑 전략으로 바꿔서 영속성 문제를 영속성 계층에 가둘 수 있게 한다.
- 쿼리 작업을 한다면 매핑 오버헤드를 줄이고 빠르게 코드를 짜기 위해 '매핑하지 않기' 전략이 웹 계층과 애플리케이션 계층 사이, 애플리케이션 계층과 영속성 계층 사이에서 첫 번째 선택지가 되어야 한다. 하지만 애플리케이션 계층에서 영속성 문제나 웹 문제를 다뤄야 하게 되면 웹 계층과애플리케이션 계층, 애플리케이션 계층과 영속성 계층 사이에서 각각 '양방향' 매핑 전략으로 바꿔야 한다.
유지보수 가능한 소프트웨어를 만드는 데 어떻게 도움이 될까?
각 유스케이스에 대해 좁은 포트를 사용하면 유스케이스마다 다른 매핑 전략을 사용할 수 있고, 다른 유스케이스에 영향을 미치지 않으면서 코드를 개선할 수 있기 때문에 특정 상황, 특정 시점에 최선의 전략을 선택할 수 있다.
상황별로 매핑 전략을 선택하는 것은 모든 상ㅎ왕에 같은 매핑 전략을 사용하는 것보다 분명 더 어렵고 더 많은 커뮤니케이션을 필요로 하겠지만 매핑 가이드라인이 있는 한, 코드가 정확히 해야 하는 일만 수행하면서 더 유지보수하기 쉬운 코드로 돌아온다.
애플리케이션 조립하기
애플리케이션이 시작될 때 클래스를 인스턴스화하고 묶기 위해서 의존성 주입 메커니즘을 이용한다.
왜 조립까지 신경 써야 할까?
유스케이스와 어댑터를 그냥 필요할 때 인스턴스화하면 안 되는 걸까? 코드 의존성이 올바른 방향을 가리키게 하기 위해서다. 모든 의존성은 안쪽으로, 애플리케이션의 도메인 코드 방향으로 향해야 도메인 코드가 바깥 계층의 변경으로부터 안전하다.

아키텍처에 대해 중립적이고 인스턴스 생성을 위해 모든 클래스에 대한 의존성을 가지는 설정 컴포넌트가 있어야 한다. 설정 컴포넌트는 모든 내부 계층에 접근할 수 있는 원의 가장 바깥쪽에 위치하며 제공한 조각들로 애플리케이션을 조립하는 것을 책임진다.
- 웹 어댑터 인스턴스 생성
- HTTP 요청이 실제로 웹 어댑터로 전달되도록 보장
- 유스케이스 인스턴스 생성
- 웹 어댑터에 유스케이스 인스턴스 제공
- 영속성 어댑터 인스턴스 생성
- 유스케이스에 영속성 어댑터 인스턴스 제공
- 영속성 어댑터가 실제로 데이터베이스에 접근할 수 있도록 보장
설정 컴포넌트는 설정 파일이나 커맨드라인 파라미터 등과 같은 설정 파라미터의 소스에도 접근할 수 있어야 한다. 책임('변경할 이유')이 많다. 이것은 단일 책임 원칙을 위반하는게 맞지만 나머지 부분을 깔끔하게 유지하는데 도움이 된다.
평범한 코드로 조립하기
애플리케이션을 조립할 책임이 있는 컴포넌트를 구현하는 방법은 여러가지다.
의존성 주입 프레임워크의 도움 없이 애플리케이션을 만들고 있다면 평범한 코드로 이런 컴포넌트를 만들 수 있다.
import com.example.makelearnclean.account.adapter.in.web.SendMoneyController;
import com.example.makelearnclean.account.adapter.out.persistence.AccountPersistenceAdapter;
import com.example.makelearnclean.account.adapter.out.persistence.AccountRepository;
import com.example.makelearnclean.account.adapter.out.persistence.ActivityRepository;
import com.example.makelearnclean.account.application.port.SendMoneyUseCase;
import com.example.makelearnclean.account.application.service.SendMoneyService;
class Application {
public static void main(String[] args) {
AccountRepository accountRepository = new AccountRepository();
ActivityRepository activityRepository = new AccountRepository();
// 어댑터 객체 생성
AccountPersistenceAdapter adapter = new AccountPersistenceAdapter(accountRepository, activityRepository);
// useCase
SendMoneyUseCase sendMoneyUseCase = new SendMoneyService(AccountPersistenceAdapter, AccountPersistenceAdapter);
SendMoneyController sendMoneyController = new SendMoneyController(SendMoneyController);
startProcessingWebReqeusts(sendMoneyController);
}
}그냥 예시 코드다. main 에서 웹 컨트롤러부터 영속성 어댑터까지, 필요한 모든 클래스의 인스턴스로 생성한 후 함께 연결한다.
이 방식은 가장 평범하지만 몇 가지 단점이 있다.
- 프로덕션 코드라면 번거롭게 하나씩 다 주입해주어야 한다.
- 각 클래스가 속한 패키지 외부에서 인스턴스를 생성하기 때문에 클래스들은 모두 public 이다. 이렇게 된다면 유스케이스가 영속성 어댑터에 직접 접근하는 것을 막지 못한다. package-private 접근 제한자를 이용해서 원치 않은 의존성을 피할 수 없다
이런 단점들을 보완해주는게 스프링이다.
스프링의 클래스패스 스캐닝으로 조립하기
스프링 프레임워크를 이용해서 애플리케이션을 조립한 결과물을 애플리케이션 컨텍스트 라고 한다. 애플리케이션 컨텍스트는 애플리케이션을 구성하는 모든 객체 (bean) 을 포함한다.
- classpath scanning
스프링은 클래스패스 스캐닝으로 접근 가능한 모든 클래스를 확인해서 @Component 애너테이션이 붙은 클래스를 찾는다. 그리고 찾은 클래스들의 객체를 생성하는데 모든 필드를 인자로 받는 생성자를 가지고 있어야 한다.
클래스패스 스캐닝의 단점은 클래스에 프레임워크에 특화된 애너테이션을 붙여아 한다는 것이다. 이는 다른 개발자들이 사용할 라이브러리나 프레임워크를 만드는 입장에서는 사용하지 말아야 할 방법이다.
또 다른 단점은 @Component 어노테이션이 포함된 모든 클래스를 포함하기 때문에 의도하지 않은 사이드이펙트를 발생시킬 수 있다.
스프링의 자바 컨피그로 조립하기
@Component 와 비슷하게 동작하지만 @Configuration은 설정 파일로 지정된 클래스들만 선택하기 때문에 @Component 보다 비교적 안전하게 사용할 수 있다.
import com.example.makelearnclean.account.adapter.out.persistence.AccountMapper;
import com.example.makelearnclean.account.adapter.out.persistence.AccountPersistenceAdapter;
import com.example.makelearnclean.account.adapter.out.persistence.AccountRepository;
import com.example.makelearnclean.account.adapter.out.persistence.ActivityRepository;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
@Configuration
@EnableJpaRepositories
class PersistenceAdapterConfiguration {
@Bean
AccountPersistenceAdapter accountPersistenceAdapter(AccountRepository accountRepository, ActivityRepository activityRepository, AccountMapper accountMapper) {
return new AccountPersistenceAdapter(accountRepository, activityRepository, accountMapper);
}
@Bean
AccountMapper accountMapper() {
return new AccountMapper();
}
}이런 방식의 단점은 설정 클래스가 생성하는 빈(이 경우에는 영속성 어댑터 클래스)이 설정클래스와 같은 패키지에 존재하지 않는다면 이 빈들을 Public으로 만들어야 한다. 가시성을 제한하기 위해 패키지를 모듈 경계로 사용하고 각 패키지 안에 전용 설정 클래스를 만들 수는 있지만, 하위 패키지를 사용할 수 없다.
유지보수 가능한 소프트웨어를 만드는 데 어떻게 도움이 될까?
스프링과 스프링 부트같은 프레임워크들은 개발을 편하게 해주는 다양한 기능들을 제공한다. 그 중 하나가 애플리케이션 개발자로서 우리가 제공하는 클래스들을 이용해 애플리케이션을 조립해주는 것이다.
클래스패스 스캐닝은 편리한 기능이지만, 규모가 커지면 투명성이 낮아지고 어떤 빈이 컨텍스트에 올라온느지 정확히 알 수 없게되며, 테스트에서 컨텍스트의 일부만 독립적으로 띄우기가 어려워진다.
반면 애플리케잇녀 조립을 책임지는 전용 설정 컴포넌트를 만들면 애플리케이션이 이러한 책임('변경할 이유')으로부터 자유로워진다.
아키텍처 경계 강제하기
일정 규모 이상의 모든 프로젝트에서는 시간이 지나면서 아키텍처가 서서히 무너지게 된다. 계층간의 경계갸ㅏ 약화되고, 코드는 점점 더 테스트하기 어려워지고, 새로운 기능을 구현하는 데 점점 더 많은 시간이 든다.
경계와 의존성
'경계를 강제한다'는 것이 어떤 의미인가?

아키텍처 경계를 강제한다는 것은 의존성이 올바른 방향을 향하도록 강제하는 것을 의미하며, 위 사진에서 허용되지 않은 의존성은 점선 화살표로 표시되어 있는 부분이다. 위 사진에서 바로 점선 화살표 처럼 잘못된 부분을 없앨 수 있는 방법이을 알아본다.
접근 제한자
package-private 제한자가 중요한 이유는 자바 패키지를 통해 클래스들을 응집적인 '모듈'로 만들어주기 때문이다. 그럼 모듈의 진입점으로 활용되는 클래스들만 골라서 public 으로 만들어주면 의존성이 잘못된 방향을 가리켜서 규칙을 위반할 위험이 줄어든다.
package-private 제한자는 규모가 작은 모듈에서 효과적이다. 클래스가 많이 생기기 시작하면 하위 패키지를 만들게 되는데, 하위 패키지는 자바가 다른 패키지로 인식하기 때문에 public으로 만들어야한다. 이는 아키텍처 의존성 규칙이 꺠질 수 있는 환경이 만들어지게 된다.
컴파일 후 체크
컴파일 후 체크(post-compile check)를 도입한다. 코드가 컴파일된 후에 런타임에 체크한다는 뜻인데, 이런 런타임 체크는 지속적인 통합 빌드 환경에서 자동화된 테스트 과정에서 가장 잘 동작한다.
자바용 도구로 ArchUnit 을 사용하면 의존성 방향이 기대한 대로 잘 설정되어 있는지 체크할 수 있는 API를 제공한다. 의존성 규칙 위반을 발견하면 예외를 던지며, 이 도구는 JUnit과 같은 단위 테스트 프레임워크 기반에서 가장 잘 동작하며 의존성 규칙을 위반할 경우 테스트는 실패한다.
class DependencyRuleTests {
@Test
void domainLayerDoesNotDependOnApplicationLayer() {
noClasses()
.that()
.resideInPackage("package.example..")
.should()
.dependOnClassesThat()
.resideInAnyPackage("package.example..")
.check(new ClassFileImporter())
,importPackages("package.."));
}
}ArchUnit API를 이용하면 적은 작업만으로 육각형 아키텍처 내에 관련된 모든 패키지를 명시할 수 있는 일종의 도메인 특화 언어 를 만들 수 있고, 패키지 사이의 의존성 방향을 자동으로 체크할 수 있다.
class DependencyRuleTests{
@Test
void validateRegistrationContextArchitecture() {
HexagonalArchitecture.boundedContext("account")
.withDomainLayer("domain")
.withAdaptersLayer("adapter")
.incoming("web")
.outgoing("persistence")
.and()
.withApplicationLayer("application")
.services("service")
.inncomingPorts("port.in")
.outgoingPorts("port.out")
.and()
.withConfiguration("configuration")
.check(new ClassFileImporter().importPackages("package.."));
}
}- 바운디드 컨텍스트의 부모 패키지 지정 (단일 바운디드 컨텍스트면 애플리케이션 전체)
- 도메인, 어댑터, 애플리케이션 설정 셰층에 해당하는 하위 패키지 지정
- check()는 몇 가지 체크를 실행하고 패키지 의존성이 의존성 규칙을 따라 유효하게 설정됐는지 검증
패키지명을 지정할때 오타가 나거나 패키지명을 리팩토링하거나 하면 테스트 코드도 동작하지 않는다. 이런 상황을 방지하기 위해 클래스를 찾지 못했을 때 실패하는 테스트를 추가해야한다.
빌드 아티팩트
빌드 아티팩트는 빌드 프로세스의 결과물이다. 빌드 도구의 주요한 기능 중 하나는 의존성 해결이다. 빌드 아티팩트로 변환하기 위해 빌드 도구가 가장 먼저 할 일은 코드베이스가 의존하고 있는 모든 아티팩트가 사용 가능한지 확인하는 것이다. 이를 활용해서 모듈과 아키텍처의 계층간의 의존성을 강제할 수 있다.
각 모듈 혹은 계층에 대해 전용 코드베이스와 빌드 아티팩트로 분리된 모듈을 만들 수 있다. 각 모듈의 빌드 스크립트에서는 아키텍처에서 허용하는 의존성만 지정한다. 클래스들이 클래스패스에 존재하지도 않아 컴파일 에러가 발생하기 때문에 개발자들은 실수로 잘못된 의존성을 만들 수 없다.
'etc' 카테고리의 다른 글
| [react] openlayers - react - vworld (3) | 2024.10.22 |
|---|---|
| [Network] react sprignboot CORS (9) | 2024.10.09 |
| [만들면서 배우는 클린 아키텍처] 7장 정리 (1) | 2024.09.14 |
| [만들면서 배우는 클린 아키텍처] 5장, 6장 정리 (0) | 2024.09.14 |
| [만들면서 배우는 클린 아키텍처] 1장, 2장, 3장, 4장 정리 (0) | 2024.09.14 |